
AI(人工知能)は、魔法のように答えを出してくれるわけではありません。実は、裏側でたくさんの計算や「学習」を行っています。
この記事では、AIがどのようにして賢くなるのか、その仕組みを中学生でもわかるように噛み砕いて解説します。「機械学習」や「ディープラーニング」といった少し難しそうな言葉も、具体的なイメージをつかめば怖くありません。
生成AIパスポート試験で頻出の重要キーワードを、日常生活の例えを交えながら整理していきましょう!
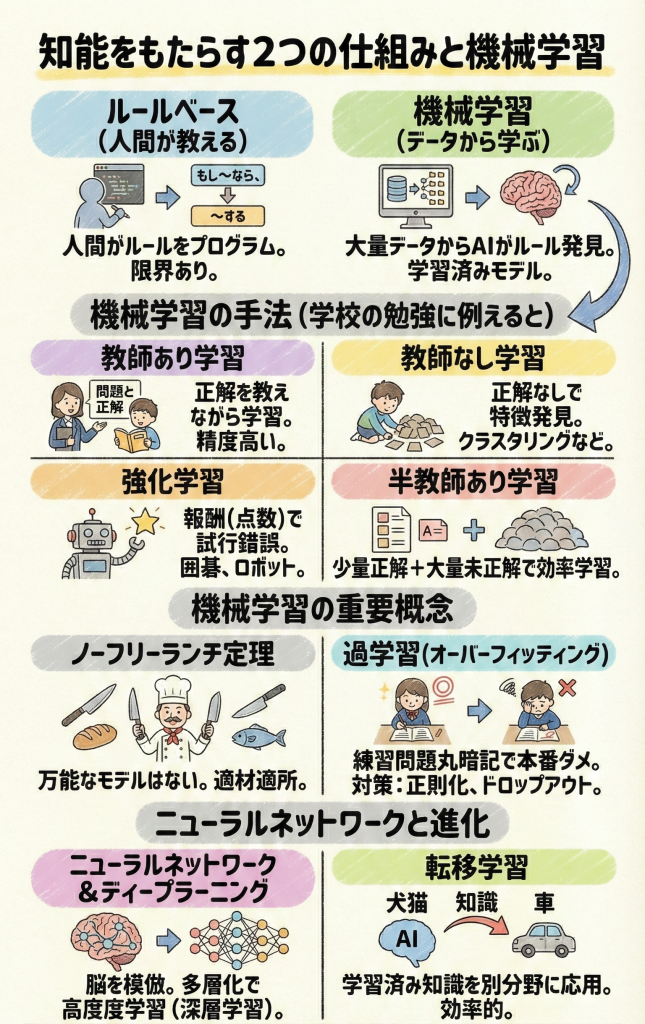
知能をもたらす2つの仕組み
コンピュータに「知能」のような働きをさせるための方法は、大きく分けて2種類あります。
- 人間がすべてのルールを教える方法(ルールベース)
- コンピュータ自身に大量のデータから学ばせる方法(機械学習)
現在のAIブームの中心は、後者の機械学習ですが、まずは基本となるこの2つの違いを理解しましょう。
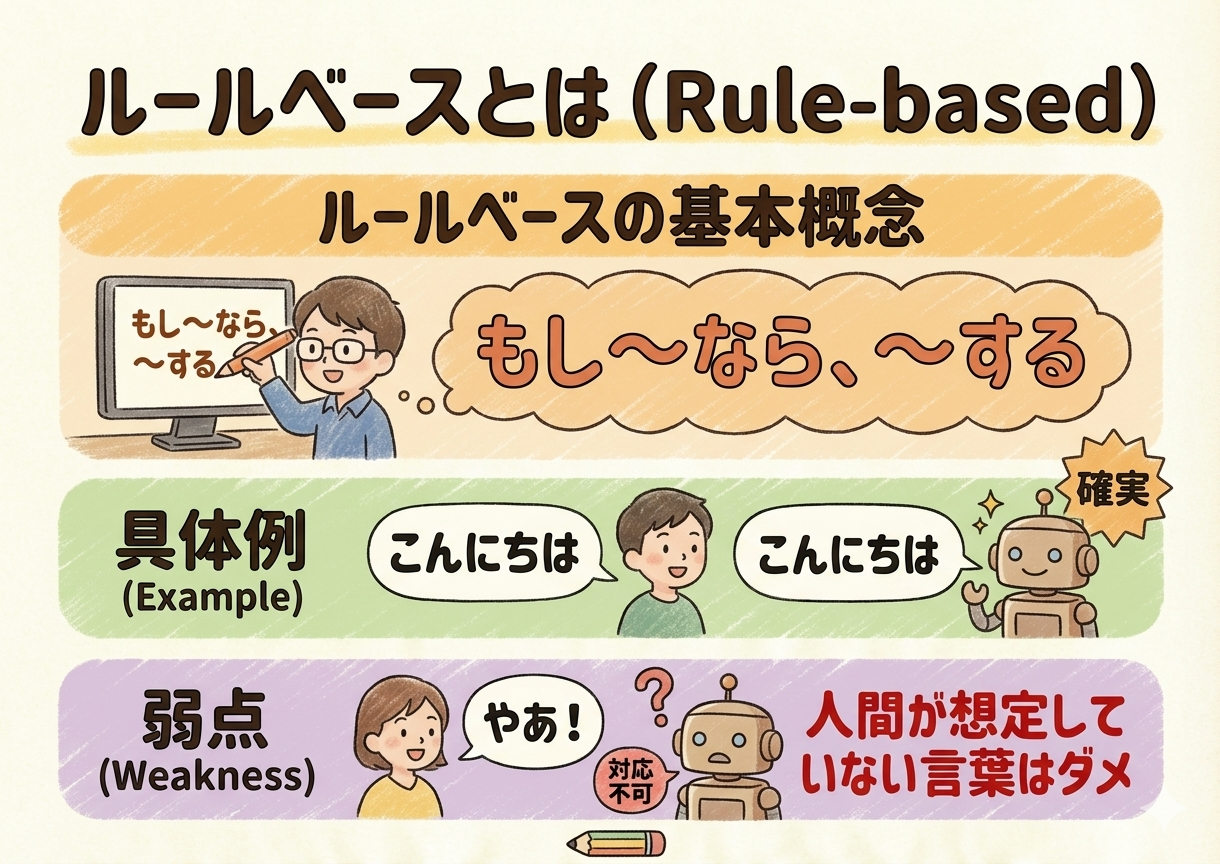
ルールベースとは
ルールベースとは、「もしAなら、Bをする(IF-THENルール)」という規則を、人間が手作業でプログラムする方法です。
例えば、お客様窓口の自動応答で「『料金』という単語が含まれていたら、料金案内のページURLを返す」というルールを設定します。これは確実ですが、「お金のこと」「支払いについて」など、人間が想定・登録していない言葉をかけられると、「分かりません」と対応できなくなってしまいます。
昔のAIや初期のチャットボットはこのルールベースが主流でしたが、人間の使う言葉の多様さ(方言や表記揺れなど)をすべてルールとして書き出すのには限界がありました。
機械学習とは
機械学習は、大量のデータを読み込ませて、コンピュータ自身に「ルール」や「特徴的なパターン」を見つけ出させる方法です。
人間がいちいち「猫の耳は三角で、ヒゲが3本あって…」とルールを書かなくても、AIに何万枚もの「猫の画像」と「猫以外の画像」を見せることで、AI自身が「猫とはこういうものだ」という特徴を自ら学習します。
この学習によって出来上がった、未知のデータに対しても判断を下せるプログラムのことを学習済みモデルと呼びます。

機械学習の手法
機械学習には、学習のさせ方によっていくつか種類があります。学校の勉強スタイルに例えてみましょう。
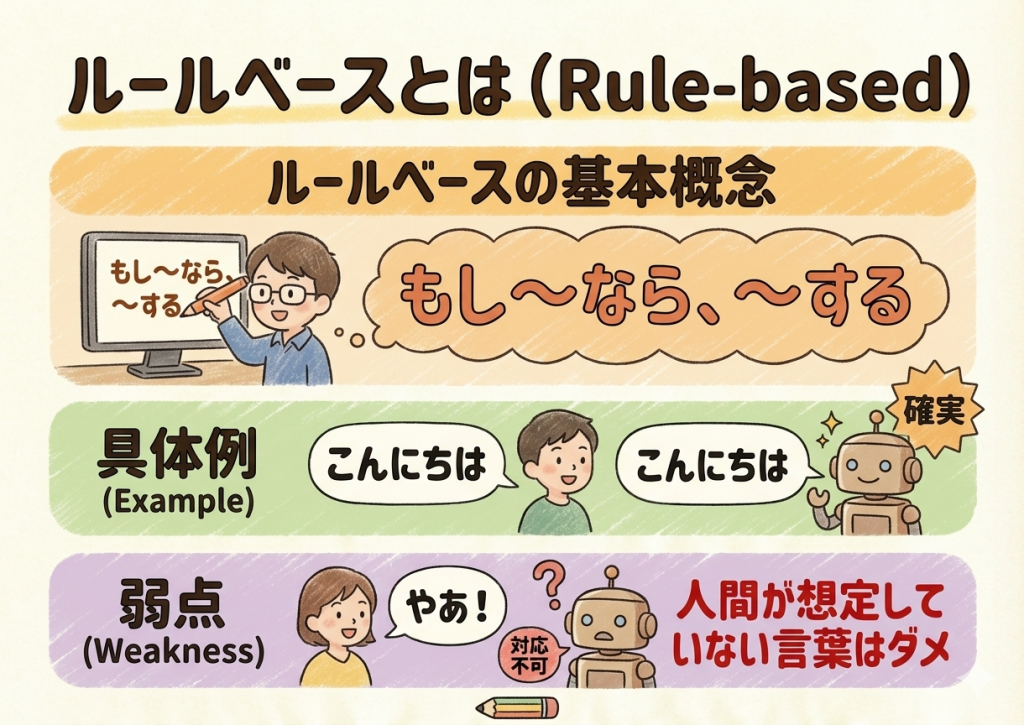
教師あり学習
問題と正解(ラベル)がセットになったデータを使って学習する方法です。
「これは猫の画像です(正解)」「これは犬の画像です(正解)」と、先生が答えを教えながら学習させます。迷惑メールフィルター(「これは迷惑メール」「これは通常メール」と学習させる)など、現在のビジネスで最も一般的に使われており、精度の高いAIが作れます。
教師なし学習
正解を与えずに、大量のデータだけを渡して「似たものを集めて」「何か特徴を見つけて」と学習させる方法です。
- クラスタリング:似たもの同士をグループ分けすること。例えば、スーパーの購買データから、正解がなくても「まとめ買い派」「毎日少しずつ買う派」「お惣菜中心派」など、顧客を自動的にグループ分けしてマーケティングに活かします。
- 次元削減:データが複雑すぎる場合、重要な情報(本質)だけを抜き出して、データをスッキリさせること。
強化学習
「正解」を教える代わりに、上手くできたら「報酬(点数)」を与える方法です。
自転車の練習に似ています。転んだら痛い(マイナス)、前に進めたら嬉しい(報酬)。AIが試行錯誤を繰り返し、最も点数が高くなる行動手順を自ら学びます。囲碁・将棋のAIや、自動運転、ロボットの歩行訓練などで使われます。
半教師あり学習
「少量の正解付きデータ」と「大量の正解なしデータ」を組み合わせて学習する方法です。
すべての画像やデータに人間が手作業で正解(ラベル)をつけるのは膨大なコストがかかるため、効率よく賢くさせるための現実的なアプローチとして使われます。
機械学習の考え方
ここで一つ、AIの世界で有名な定理を紹介します。
ノーフリーランチ定理(タダ飯はない定理)という面白い名前の法則があります。これは、「あらゆる問題に対して、常に最高の性能を発揮する万能なAIモデルは存在しない」という意味です。
つまり、ある特定の問題(例:画像認識)に特化して素晴らしい性能を発揮するAIを作ると、別の問題(例:音声認識)にはまったく役に立たなくなります。「どんな食材でも完璧に切れる万能包丁はない(パン切り包丁はパンには最適だが、魚をさばくのには向かない)」と覚えると分かりやすいでしょう。
人間の脳とニューラルネットワーク
現在のAIの急激な進化を支えているのが、人間の脳の仕組みを真似した技術です。
ニューロンとシナプス
人間の脳には数百億個のニューロン(神経細胞)があり、それらがシナプスという結合部分で複雑につながり、電気信号をバケツリレーのように送り合うことで「考える」という処理を行っています。
人工ニューロンとニューラルネットワーク
この脳のバケツリレーの仕組みを数式でコンピュータ上に再現したものを人工ニューロン(ノード)と呼び、これらを網の目のように何層にも繋ぎ合わせたモデルをニューラルネットワークと呼びます。
ディープラーニング
ニューラルネットワークの層(隠れ層)を何十層、何百層にも深く重ねることで、より複雑で高度な特徴を自ら見つけ出せるようにした手法をディープラーニング(深層学習)と言います。画像生成やChatGPTなど、今のAIブームの最大の立役者です。
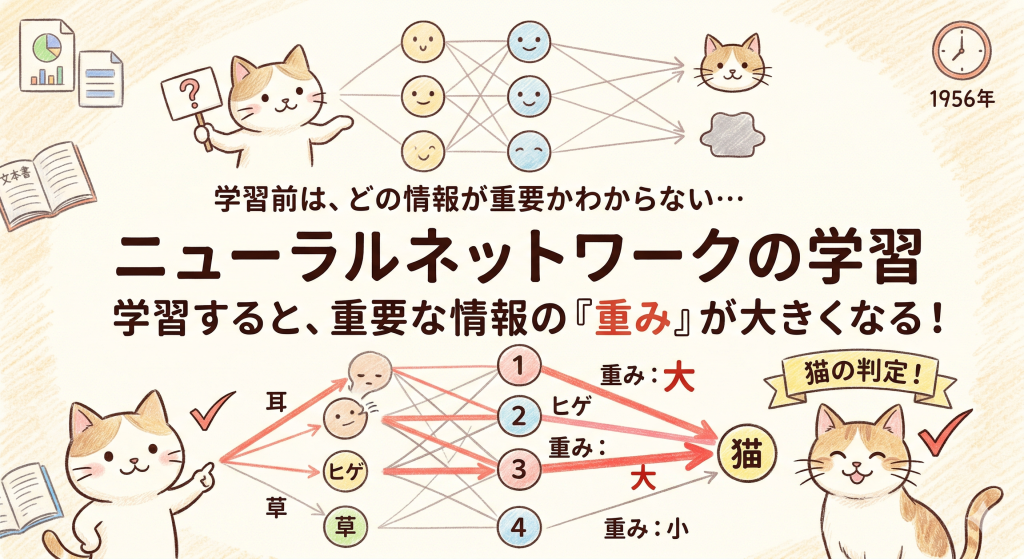
AIが画像を認識する仕組み
AIは画像をどうやって見ているのでしょうか?
ニューラルネットワークの中では、情報が隣の層に伝わる際、そのつながりの強さを重み(パラメータ)という数値で調整します。
例えば、猫を見分ける場合、「耳がとがっているか」という情報には高い重み(重要視する)をつけ、「背景が青いか」という情報には低い重み(無視する)をつけます。学習が進むにつれて、この「重みづけ」が自動的に調整されていきます。
最終的に、この無数の「重み」のバランスが最適化されることで、AIは「これは猫だ」と正しく認識できるようになるのです。
AIが自ら学習して改善される仕組み
AIの学習とは、一言で言えば「予想と正解のズレ(誤差)を小さくしていく作業」です。
ダーツの練習をイメージしてください。最初はデタラメに投げて的を外しますが、「右に大きくズレた!」という結果(誤差)をもとに、次は少し左を狙うようにフォーム(ニューラルネットワーク内の重み)を修正します。
これを何万回、何億回と繰り返すことで、徐々に的のど真ん中(正解)に当たるモデルへと進化していきます。
過学習(オーバーフィッティング)
AIが学習しすぎると、かえって困ったことが起きます。それが過学習です。
これは、手元の練習問題(訓練データ)を丸暗記しすぎてしまい、本番のテスト(未知のデータ)が解けなくなってしまう状態のことです。
「過去問の答えは完璧に暗記して100点なのに、本番で少し数字が変わっただけの応用問題が出ると0点になってしまう生徒」をイメージすると分かりやすいでしょう。
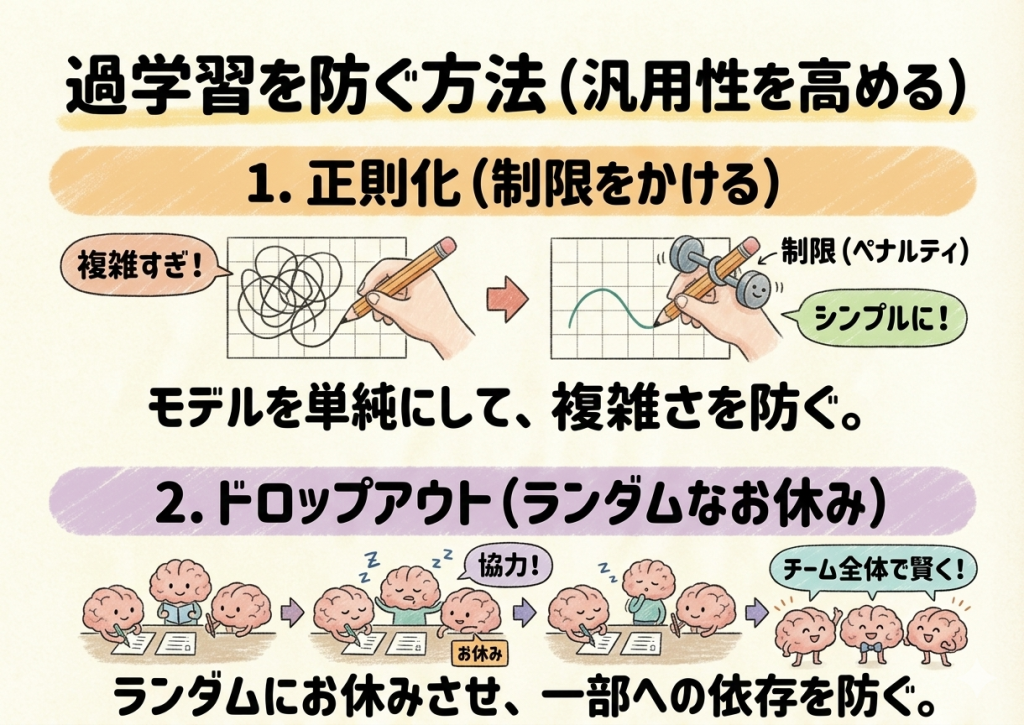
過学習を避ける手法
過学習を防ぎ、初めて見るデータにも柔軟に対応できる力(汎用性)を高めるために、AIの開発ではいくつかのテクニックが使われます。
- 正則化:モデルが複雑になりすぎないように、あえて数式に制限(ペナルティ)をかける方法。「難しく考えすぎず、シンプルに考えなさい」と指示を出すイメージです。
- ドロップアウト:学習中に、ランダムにニューロンの一部を「お休み」させる方法。一部の優秀なニューロンの丸暗記に頼りすぎるのを防ぎ、残ったメンバーだけで何とか答えを導き出す訓練をすることで、ネットワーク全体でより本質的な特徴を学べるようにします。
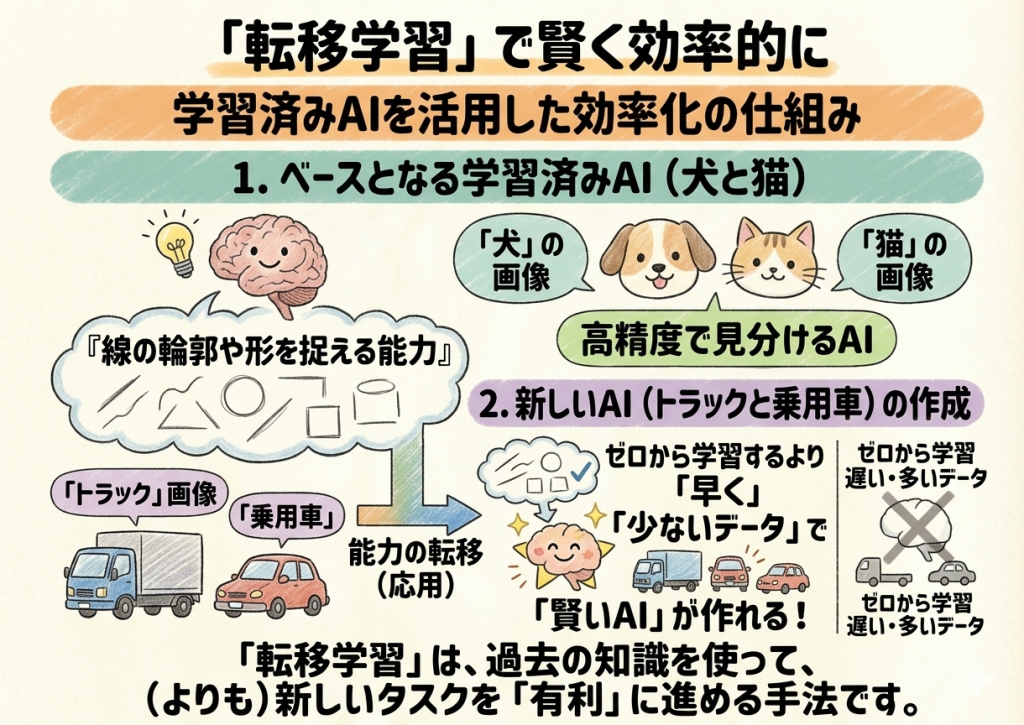
転移学習
最後に、効率よく賢くなるための裏技、転移学習を紹介します。
これは、ある分野で学習済みのモデル(知識)のベース部分を、別の似た分野にそのまま応用(お引越し)する手法です。
例えば、「英語をマスターした人」が、同じアルファベットを使う「フランス語」を新しく学ぶ場合、完全にゼロから言語を学ぶよりも習得が早いはずです。
これと同じように、「犬や猫を高精度で見分けるAI」の『画像から線の輪郭や形を捉える能力』をベースにして、「トラックと乗用車を見分けるAI」を作ると、ゼロから学習するよりもずっと早く、少ないデータで賢いAIが作れます。
まとめ
今回の記事では、AIが知能を持つための仕組みについて解説しました。
- AIには人間がルールをすべて書く「ルールベース」と、データから自ら学ぶ「機械学習」がある。
- 機械学習には「教師あり」「教師なし」「強化学習」などの手法があり、目的に応じて使い分ける。
- 脳の神経回路の仕組みを模倣した「ディープラーニング」が現在のAI進化の主流。
- 過去問の丸暗記状態である「過学習」を防ぐために、「ドロップアウト」などの工夫が必要。
- 学習済みの知識を別のタスクに活かす「転移学習」で効率よくAIを開発できる。
これらの仕組みや具体的なイメージを持っておくと、AIニュースの理解度がぐっと深まります。試験でも必ず問われる分野なので、身近な例えとセットでキーワードをしっかり復習しておきましょう!


コメント