
「AIに社内のマニュアルを覚えさせたいけれど、学習させるのは大変そう…」
「AIがもっともらしい嘘(ハルシネーション)をつくのを防ぎたい…」
そんな悩みを解決する技術として、今ビジネス現場で最も注目されているのがRAG(ラグ)です。
この記事では、生成AIパスポート試験でも頻出の重要技術であるRAGについて、その仕組みやメリット、そして「チャンク」「ベクトルデータベース」といった専門用語を、初心者にもわかるように噛み砕いて解説します。
RAGとは
RAG(ラグ)とは、Retrieval-Augmented Generation(検索拡張生成)の略です。
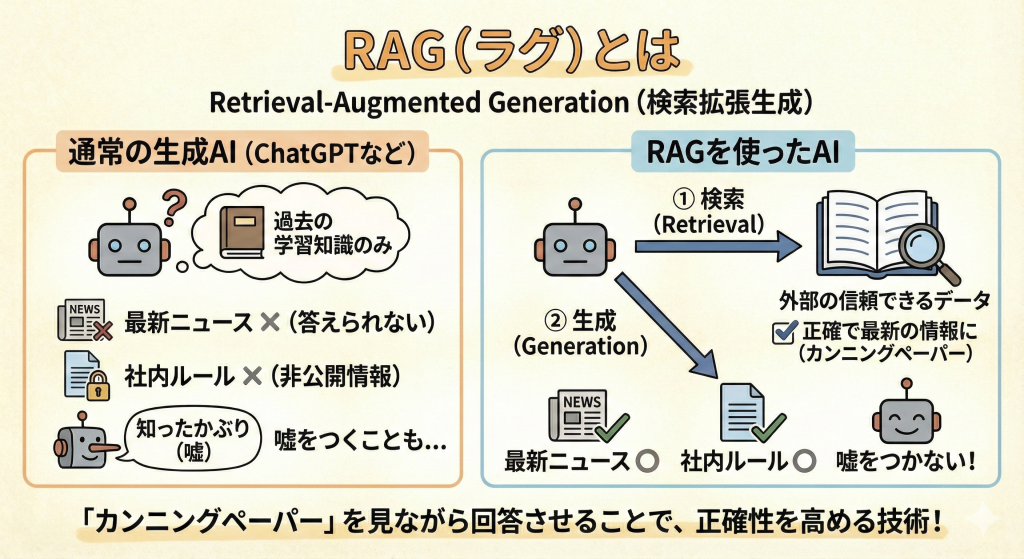
簡単に言うと、「AIにカンニングペーパー(外部の信頼できるデータ)を持たせて、それを見ながら回答させる技術」のことです。
通常の生成AI(ChatGPTなど)は、過去に学習した知識だけで答えようとします。そのため、学習していない最新ニュースや、非公開の社内ルールについては答えられなかったり、知ったかぶりをして嘘をついたりします。
RAGを使うと、AIはまず「答えが載っていそうな資料」を検索(Retrieval)し、その内容を参考にして回答を生成(Generation)します。これにより、正確で最新の情報に基づいた回答が可能になります。
RAGの歴史と発展
RAGの概念は、2020年にMeta(旧Facebook)の研究チームによって提唱されました。
当時、大規模言語モデル(LLM)には2つの大きな課題がありました。
- 知識の期限切れ:学習データが古いと、最近の出来事を知らない。
- 再学習のコスト:新しい知識を覚えさせる(ファインチューニングする)には、莫大な時間とお金がかかる。
「毎回AIを再学習させるのは大変だから、必要な時に辞書を引かせればいいじゃないか」という発想で生まれたのがRAGです。
その後、ChatGPTなどのLLMが爆発的に普及する中で、「社内データ活用」の切り札として急速に発展しました。
RAGの仕組みとメリット
RAGがどのように動いているのか、その裏側の仕組みを重要なキーワードと共に解説します。
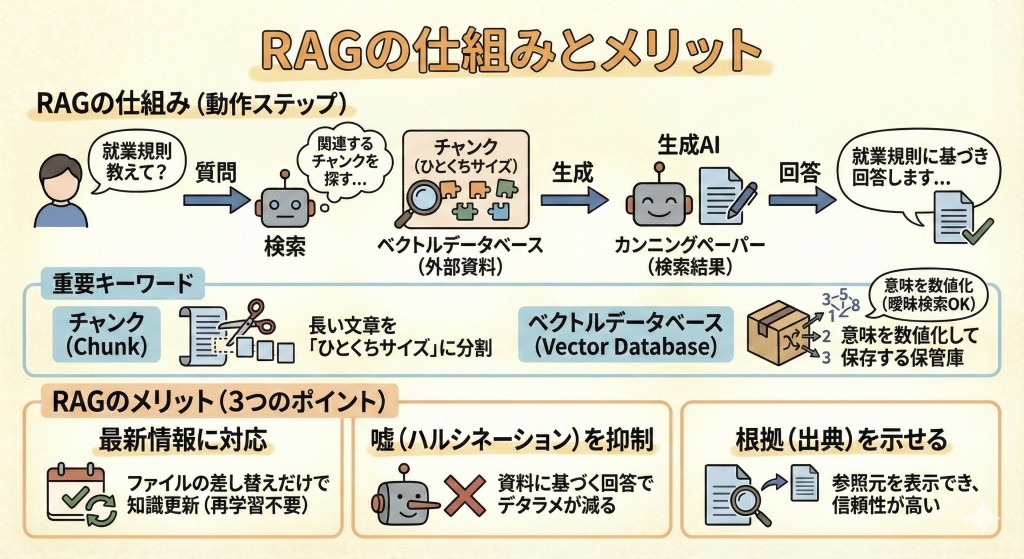
RAGの動作ステップ
- 質問:ユーザーがAIに質問する(例:「就業規則について教えて」)。
- 検索(Retrieval):AIは回答する前に、連携された外部データベース(社内マニュアルなど)から、質問に関連する文章を探し出す。
- 生成(Generation):検索で見つけた情報(カンニングペーパー)とユーザーの質問をセットにして、「この資料に基づいて回答して」とAIに指示を送る。
- 回答:AIが資料の内容を要約・整理して回答する。
重要キーワード解説
この仕組みを実現するために、以下の2つの技術が使われています。
チャンク(Chunk)
長い文章(マニュアルや契約書など)を、AIが扱いやすいように「ひとくちサイズ」に分割したものです。
本1冊をまるごと検索するのは大変なので、段落やページごとに細かく区切って(チャンク化して)保存しておきます。
ベクトルデータベース
分割したチャンクを保存しておく特別な保管庫です。
ここでは、文章をそのまま保存するのではなく、「意味」を数値化(ベクトル化)して保存します。
これにより、単語が完全に一致していなくても、「『車』と『自動車』は意味が近い」といった判断ができ、曖昧な質問でも的確な資料を探し出せるようになります。
RAGのメリット
- 最新情報に対応できる:データベースのファイルを差し替えるだけで、AIの知識を更新できる(再学習が不要)。
- ハルシネーション(嘘)の抑制:「資料に書いてあることだけ」を答えさせることで、デタラメな回答が減る。
- 根拠(出典)を示せる:「この回答はマニュアルのP.15に基づいています」と参照元を表示できるので、信頼性が高い。
RAGのユースケース
RAGは具体的にどのような場面で使われているのでしょうか。
社内ヘルプデスク・ナレッジ検索
最も多い活用例です。社内の大量のPDFマニュアルや規定集をRAGに読み込ませることで、社員からの「経費精算のやり方は?」「有給休暇のルールは?」といった質問に即座に答えるAIボットが作れます。
カスタマーサポート
自社製品の取扱説明書やFAQデータを元に、顧客からの問い合わせに自動回答するシステムです。オペレーターの負担を減らし、24時間対応が可能になります。
契約書や技術文書のレビュー支援
過去の契約書データベースを参照しながら、新しい契約書のチェックを行ったり、類似案件を探し出したりする業務支援に使われます。
まとめ
今回の記事では、RAGについて解説しました。
- RAG(検索拡張生成):外部データを検索(Retrieval)して、それを元に回答を生成(Generation)する技術。
- メリット:AIに再学習させなくても、最新情報や社内データに基づいた正確な回答ができる。
- 仕組み:文章をチャンク(小分け)にし、ベクトルデータベース(意味の保管庫)に入れて検索する。
試験では「ファインチューニング(再学習)との違い」や「ハルシネーション対策として有効なのはどっち?」といった比較問題が出やすいです。「RAG=カンニングペーパー方式」と覚えておけばバッチリです!

コメント