
ChatGPTや画像生成AIが当たり前のように使われるようになりましたが、これらの技術はある日突然生まれたわけではありません。
生成AI(ジェネレーティブAI)の進化は、数多くの研究者たちが「いかにしてコンピュータにデータを理解させ、新しいものを作らせるか」に挑んできた歴史そのものです。
この記事では、生成AIの基礎となる初期のモデルから、画像生成の立役者であるGAN、そして現在のAIブームの決定打となったTransformerやBERTまで、その進化の系譜をわかりやすく解説します。
生成AIの源流|画像生成AIはどう生まれた?(GAN・VAE)
まずは、AIが「データの特徴」をつかみ、画像を生成できるようになるまでの流れを見ていきましょう。
初期の生成モデル
生成AIの歴史は古く、初期にはボルツマンマシンや、それを扱いやすく改良した制約付きボルツマンマシンといったモデルが提案されました。これらは確率を使ってデータのパターンを学習するものでしたが、計算が非常に大変でした。
CNN(畳み込みニューラルネットワーク)
画像処理の分野で革命を起こしたのがCNN(畳み込みニューラルネットワーク)です。
CNNは、画像全体を一度に見るのではなく、小さなフィルターで画像をスキャン(畳み込み)していくことで、「ここに目がある」「ここに線がある」といった特徴を効率よく抽出します。これは人間の視覚野の仕組みをヒントに作られており、後述する画像生成AIの基礎部品として使われています。
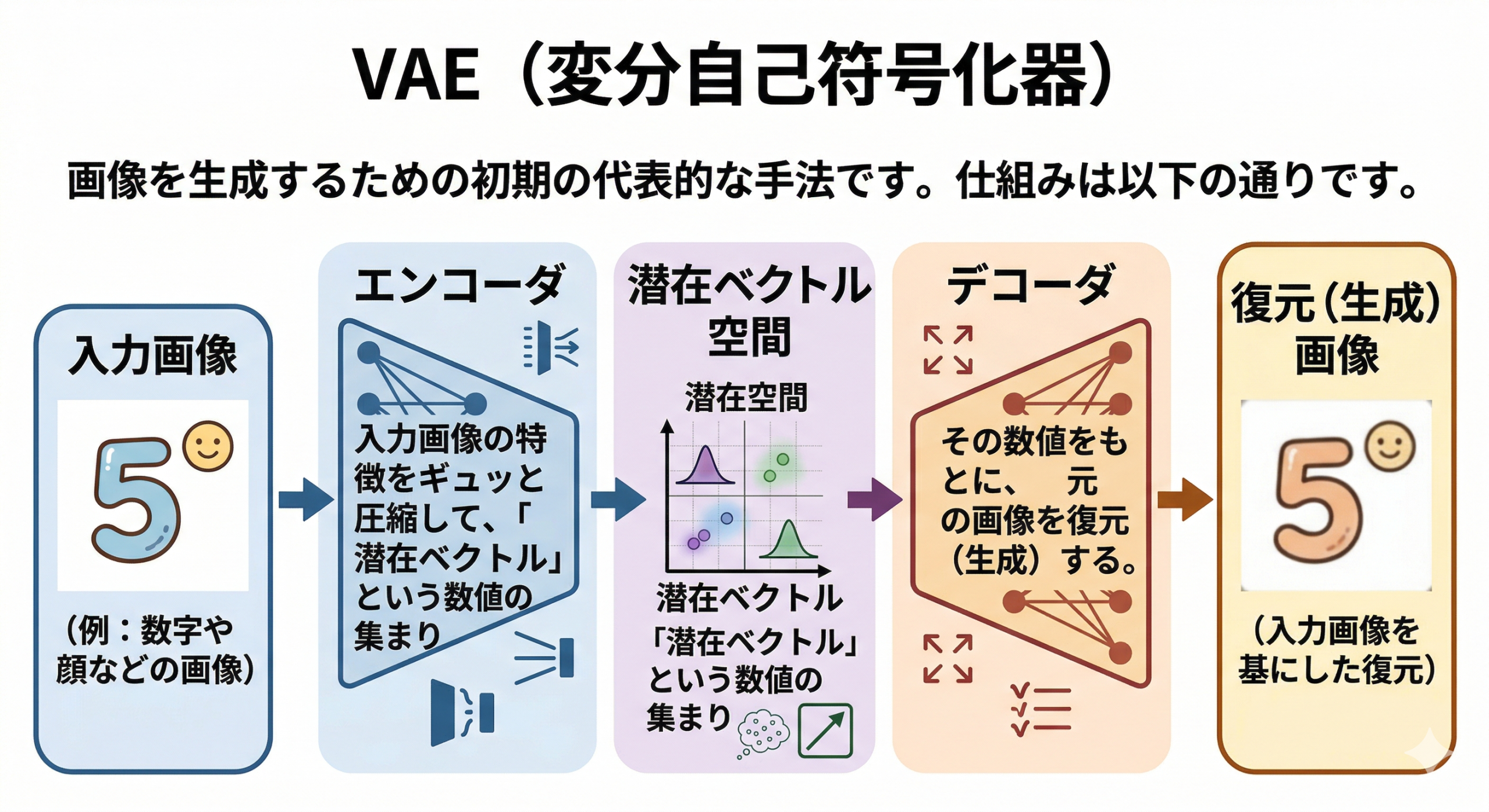
VAE(変分自己符号化器)
画像を生成するための初期の代表的な手法がVAE(変分自己符号化器)です。仕組みは以下の通りです。
- エンコーダ:入力画像の特徴をギュッと圧縮して、「潜在ベクトル」という数値の集まりに変換する。
- デコーダ:その数値をもとに、元の画像を復元(生成)する。
VAEの特徴は、学習時にあえて「ノイズ(乱数)」を混ぜることです。これにより、AIは少し曖昧なデータからでも画像を生成できるようになり、「似ているけれど新しい画像」を作り出せるようになりました。
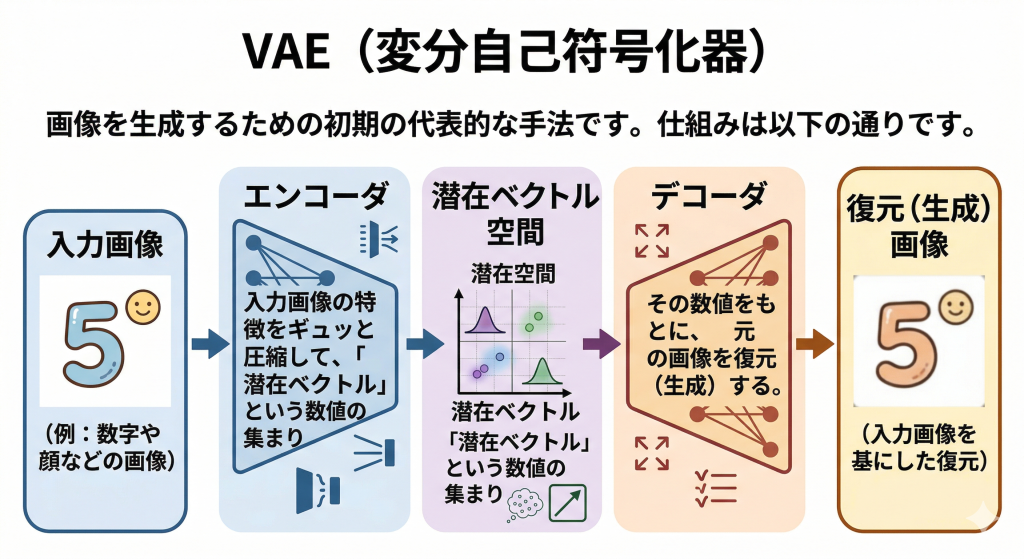
GAN(敵対的生成ネットワーク)
画像生成のクオリティを劇的に向上させたのがGAN(敵対的生成ネットワーク)です。これは「2つのAIを戦わせる」という画期的なアイデアで生まれました。
- 生成器(Generator):偽物の画像を作る「偽造犯」役
- 識別器(Discriminator):本物か偽物かを見抜く「警察」役
偽造犯はバレないように絵が上手くなり、警察はダマされないように鑑定が上手くなる…。このイタチごっこを繰り返すことで、最終的に人間でも見分けがつかないレベルの画像が生成できるようになります。
言語AIはどう進化した?RNN・LSTMから理解する
次に、文章や音声のような「順番のあるデータ(シーケンスデータ)」を扱うAIの進化を見てみましょう。
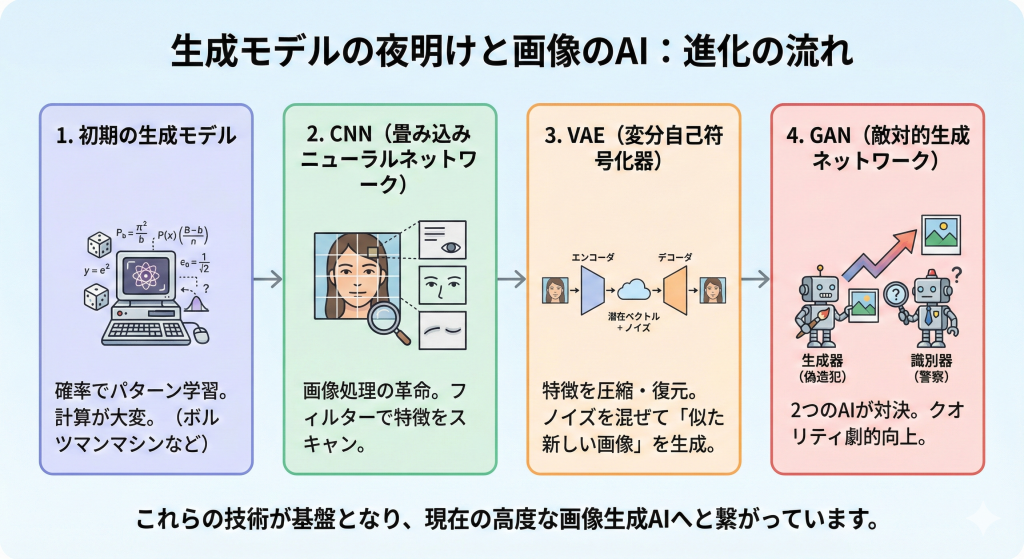
RNN(回帰型ニューラルネットワーク)
文章などの連続したデータを扱うために開発されたのがRNN(回帰型ニューラルネットワーク)です。
従来のAIは「前のデータ」を覚えていられませんでしたが、RNNは隠れ層(中間層)の一部を「記憶(リカレント層)」として次の処理に回すことで、文脈を考慮できるようにしました。
しかし、RNNには「文章が長くなると、最初の方の内容を忘れてしまう」という弱点がありました。
LSTM(長・短期記憶)
RNNの「忘れん坊」問題を解決したのがLSTM(長・短期記憶)です。
LSTMは、情報を「忘れるゲート」「覚えるゲート」などで制御し、重要な情報は長く記憶し、不要な情報はすぐに忘れるという仕組みを取り入れました。これにより、長い文章の翻訳などが実用レベルになりました。
Transformerとは?生成AIブームの決定打になった理由
2017年、Googleが発表した論文によってAIの歴史は大きく変わります。それがTransformerモデルです。
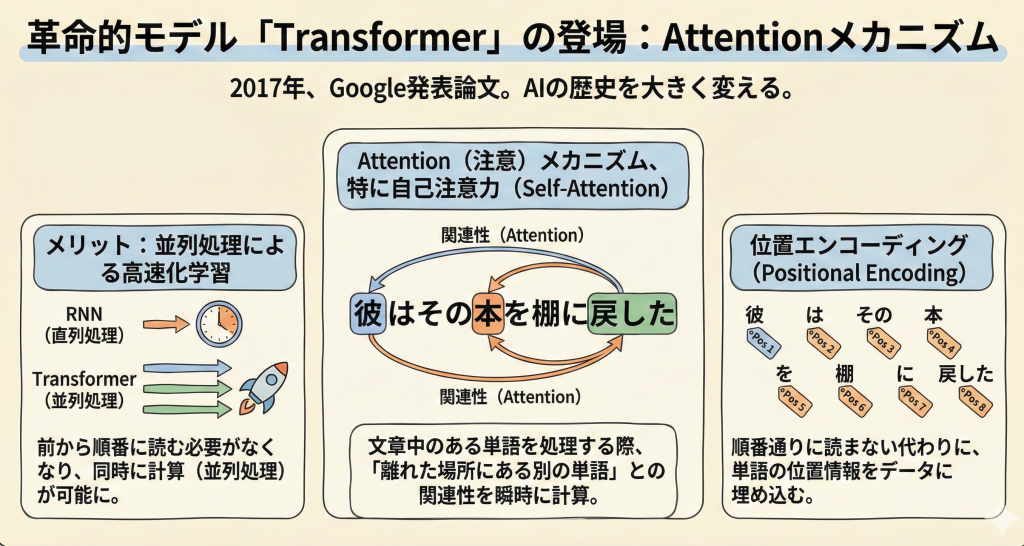
Attention(注意)メカニズム
Transformerの最大の発明は、Attention Mechanism(注意機構)、特に自己注意力(Self-Attention)です。
これは、文章中のある単語を処理する際、「離れた場所にある別の単語」との関連性(Attention層)を計算する仕組みです。
例えば「彼はその本を棚に戻した」という文で、「戻した」のが「彼」なのか「本」なのかを、文中の距離に関係なく瞬時に結びつけて理解できます。これにより、RNNのように前から順番に読む必要がなくなり、並列処理による高速な学習が可能になりました。
また、順番通りに読まない代わりに、単語の位置情報を位置エンコーディングという技術でデータに埋め込んでいます。
GPTとBERTの違い|Transformer後の2大モデル
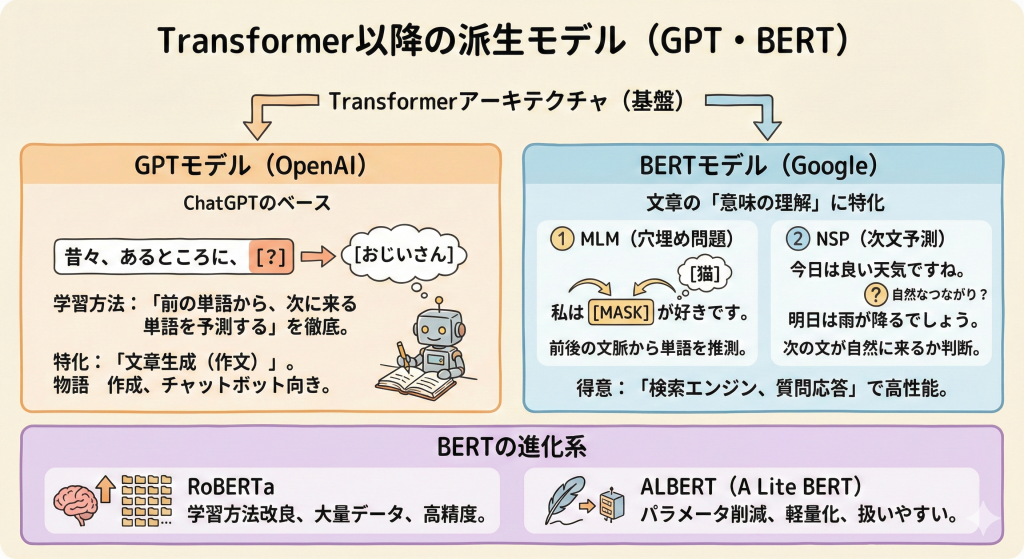
Transformerのアーキテクチャ(設計図)をベースに、2つの巨大なモデルが誕生しました。
GPTモデル(OpenAI)
ChatGPTのベースとなっているのが、OpenAIが開発したGPTモデルです。
GPTは「前の単語から、次に来る単語を予測する」という学習を徹底的に行います。これは文章を生成すること(作文)に特化しており、物語の作成やチャットボットに向いています。
BERTモデル(Google)
一方、Googleが開発したのがBERTモデルです。BERTは文章の「意味の理解」に特化しています。
学習方法に以下の2つの工夫があります。
- MLM(Masked Language Model):文章の一部を穴埋め問題にして、前後の文脈から単語を推測させる。
- NSP(Next Sentence Prediction):ある文の次に、別の文が来るのが自然かどうかを判断させる。
この仕組みにより、BERTは検索エンジンや質問応答システムで高い性能を発揮しました。
BERTの進化系
BERTの登場後、さらに効率化したモデルも登場しました。
- RoBERTa:BERTの学習方法を改良し、さらに大量のデータで学習させて精度を高めたモデル。
- ALBERT(A Lite BERT):パラメータを減らして軽量化し、扱いやすくしたモデル。
【まとめ】生成AI誕生までの流れ 試験で問われる5ポイント
生成AIの進化は、「データの捉え方の進化」と言えます。
- 画像:CNNで特徴をつかみ、VAEやGANで生成する。
- 時系列(文章):RNNからLSTMへ進化し、記憶力を強化。
- 現在:Transformerの登場で、文脈理解と生成能力が飛躍的に向上。そこからGPT(生成重視)とBERT(理解重視)が生まれた。
試験では、これらのアルゴリズムの名前と「何が得意か(画像か、文章か、生成か、理解か)」の組み合わせがよく問われます。この流れを頭に入れておけば、迷わず解答できるはずです!
🎓 講義もセットで学びたい方へ(講義+問題集のオールインワン)
📝 問題演習を徹底したい方へ(問題集特化・200問+模擬試験3回分)

📚 より詳細を学びたい方へ



コメント